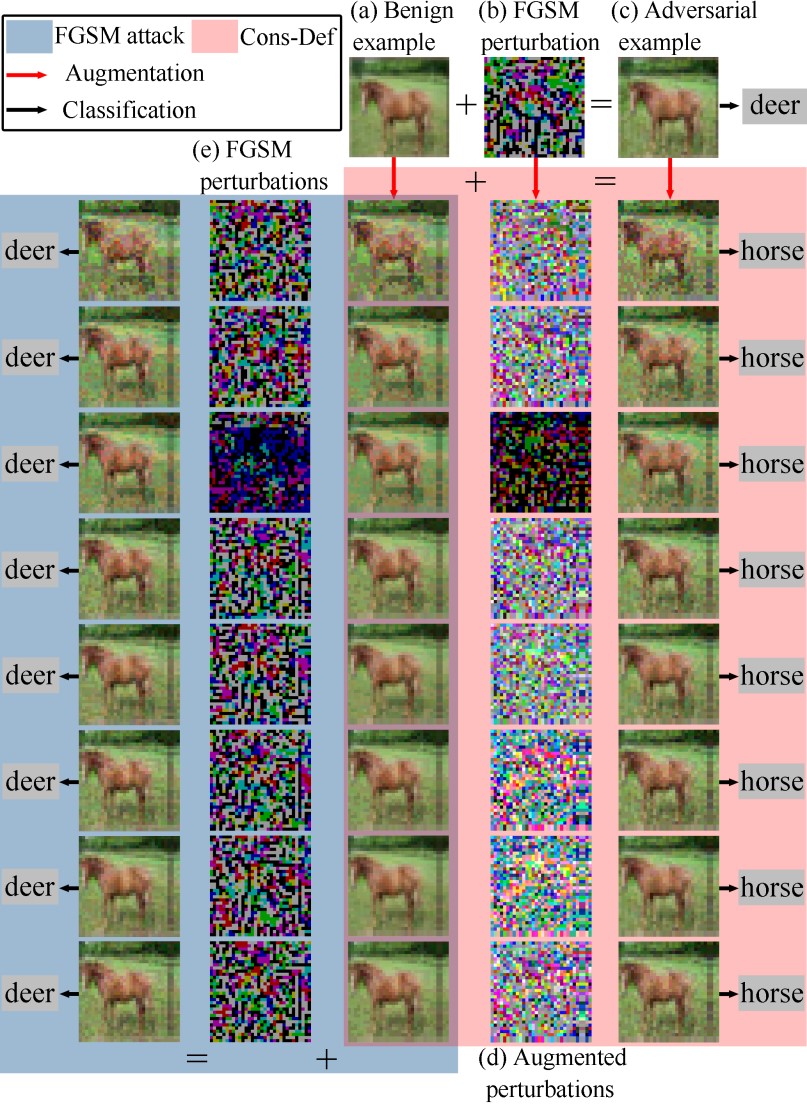
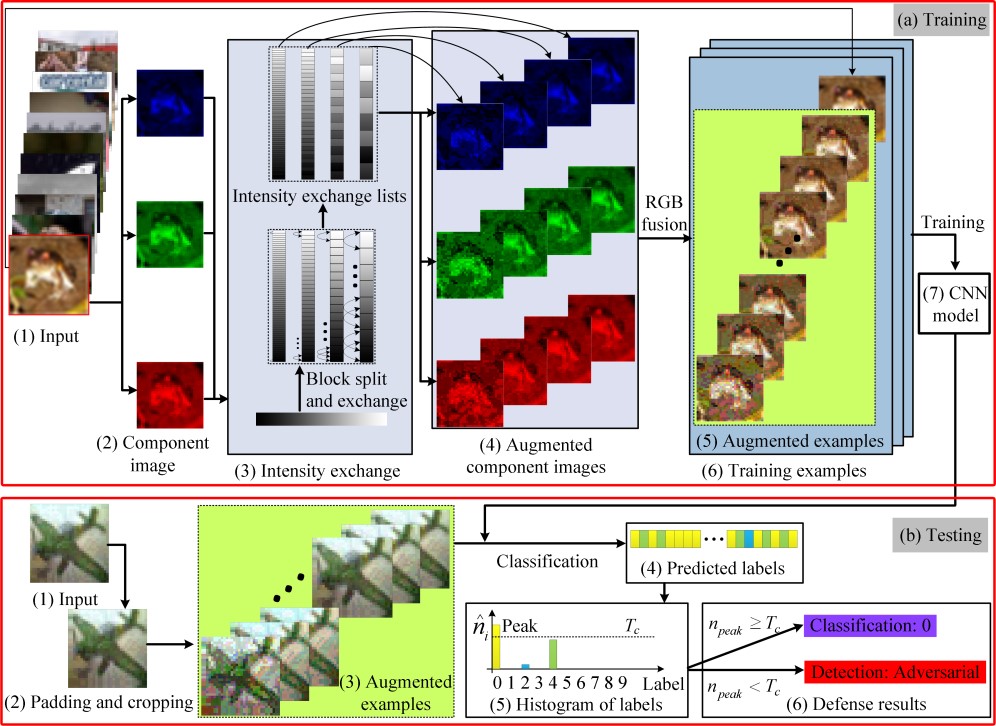
近日,由我院完成的一项人工智能安全研究成果“基于样本增强的共识对抗防御方法”被工业信息领域顶级刊物TII录用并在线出版。研究表明在正常样本中添加肉眼不可见的特定噪声,能够欺骗基于视觉的人工智能模型,使人工智能系统产生误判,这种对抗攻击使人工智能遭受安全风险。该项成果聚焦人工智能的防御问题,将样本的像素进行置乱,生成增强样本,在增强样本上进行共识防御。其动机和主要思路分别如图1和图2所示。本文提出的共识防御方法具有2个方面的创新,一是引导对抗攻击在增强样本上产生矛盾结果,而不是消除攻击;二是可以同时进行分类和检测防御,通常对抗防御进行分类防御或检测防御,而不是二者同时进行。实验结果表明,所提出的算法对白盒攻击和黑盒攻击均具有显著的防御效果。成果论文题目为“Consensus adversarial defense method based on augmented examples”,我院丁新涛副教授为成果第一作者,罗永龙教授为通讯作者;安徽师范大学和网络与信息安全安徽省重点实验室为第一完成单位。
TII (IEEE Transactions on Industrial Informatics)是IEEE旗下工业信息领域的顶级期刊,主要关注工业信息领域的理论和应用问题,包括基于知识和AI增强的自动化、与机器人和计算机视觉等相关的工业信息学、工业过程中的安全。2020年影响因子10.215,在中科院期刊分区中位列“工程技术”大类的第一区,TOP期刊,中国自动化学会(CAA)推荐的“智能感知与自主控制”领域的A类期刊。
该成果论文目前已在IEEE Xplore网站上刊登:https://ieeexplore.ieee.org/document/9762571
相关代码已在Github上公开:https://github.com/xintaoding/Cons-Def